OCR调研
概念
全称:Optical Character Recognization。
是计算机视觉研究领域的一个分支。
课题比较成熟,有商业落地项目,如:汉王OCR、百度OCR、阿里OCR。
有广泛的应用场景。
分类
主要分手写体识别和印刷体识别。
印刷体识别相对简单。挑战是印刷过程中字体会断裂或墨水粘连。目前业界已经处理的很不错,具备商业落地的水平。
手写难度在于每个人都有一套字体。目前仍然是没有功课的难关。
流程
OCR大体上分两个步骤:文字检测 + 文字预处理 + 文字识别。
文字检测的作用是发现文字在图片中的位置。通常用于在自然场景的图片里检测文字位置,如下图:

文字识别是将检测到的文字图像识别成二进制字符。
文本检测
文档文本通常不需要文本检测。
自然场景检测文字的难点:排布形式多样;文本方向多样;多种语言混合。
传统的方法将文字检测当成目标检测任务,因此会使用经典的目标检测网络来做文本检测,比如faster rcnn。
但是faster rcnn这种通用目标检测网络对文本检测的效果并不理想,没有考虑到文本的特点:
- 文本大多数程长矩形,长宽比一般大于1,普通目标检测长宽比接近1。
- 普通物体有明显的边缘轮廓,比如猫;文本没有。
- 文本中的字符之间存在间隙,容易把每个字当成检测结果,而非一整行当成结果。
目前比较流行文本检测算法:CTPN、SegLInk、EAST,前者针对水平文字检测,后两者支持倾斜文字检测。
- CTPN:特点:用分而治之的方法将文本检测任务转化为连串小尺度文本检测;引入RNN提升文本检测效果;通过边缘优化提升文本框便捷预测精度。
- SegLink:融入CTPN小尺度候选框的思路 + SSD算法思路
- EAST:端到端的文本检测方法。提升准确率和速度。
上面三种都是基于深度学的算法框架。目前文本检测都是深度学习一统天下。
图片预处理
对于文档文本识别,识别文字大致过程:
- 灰度化:将彩色图片变成灰度图
- 二值化:将灰度图变成黑白图
- 去燥:清楚黑白图上的噪点,减少干扰
- 倾斜校正:将图片顺时针或逆时针旋转,找到最佳水平位置
- 水平切割:产出每一行
- 垂直切割:产出每个字符
基于深度学习的端到端的文字识别算法不需要第6步的单词切割。
灰度化算法
颜色通常用RGB表示,格式:(R, G, B),比如红色为:RGB(255, 0, 0)。
灰色的RGB特征为R=G=B,比如(1,1,1)。
将彩色的RGB值通过某个函数,转变为灰色RGB,使得所有范围内的彩色值都能同概率的分不到灰色值范围,则这个函数就是我们要找的转换函数。
函数的形式:t = r * k + g * p + b * q ,其中k+p+q=1。
根据经验,k、p、q的取值一般为:(0.11, 0.59, 0.3) 或 (1/3, 1/3, 1/3)。
二值化算法
二值化算法的核心是要找到一个可以区分前景色RGB范围和背景色RGB范围的公式。
介绍双峰波谷最小值法:
- 将灰度图每个像素的RGB值转换为曲线图,比如:
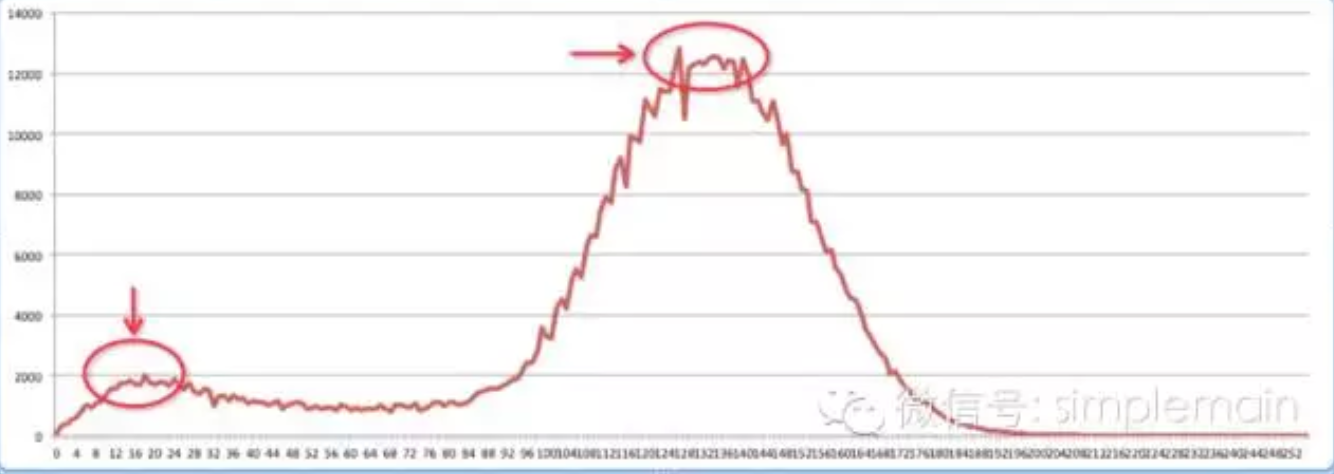
- x轴从0到255,范围覆盖灰度RGB所有可能
- y轴表示灰度图中x轴所在位置的RGB像素有几个,
- 对曲线图做迭代平滑,使得只有两个最高点,他们的值比相邻两点的大。
- 取两个最高点的值作为区分前景色和背景色的分界点。
- 通常情况下,背景色的数值比前景色多,所以上图大于分界点的数值当成背景色,小于分界点的值作为前景色,上图是白字黑字。
- 将前景色的RGB值同一调整为黑色,即
(0,0,0),将背景色RGB值统一调整为白色,即(255,255,255),二值化后的图称为一位图(bitmap)
去躁
去躁方法比较多。
基本方法是用相邻像素的比值差距作为参照点来找出噪点,如果噪点不明显,可以经过多次迭代逐步放大差距。
需要注意去躁不能过度,否则容易将正常点当噪点去掉,专业名词叫腐蚀。
迭代平滑
消除曲线图里的毛刺,消除波峰,可以将下面的图1变为图2
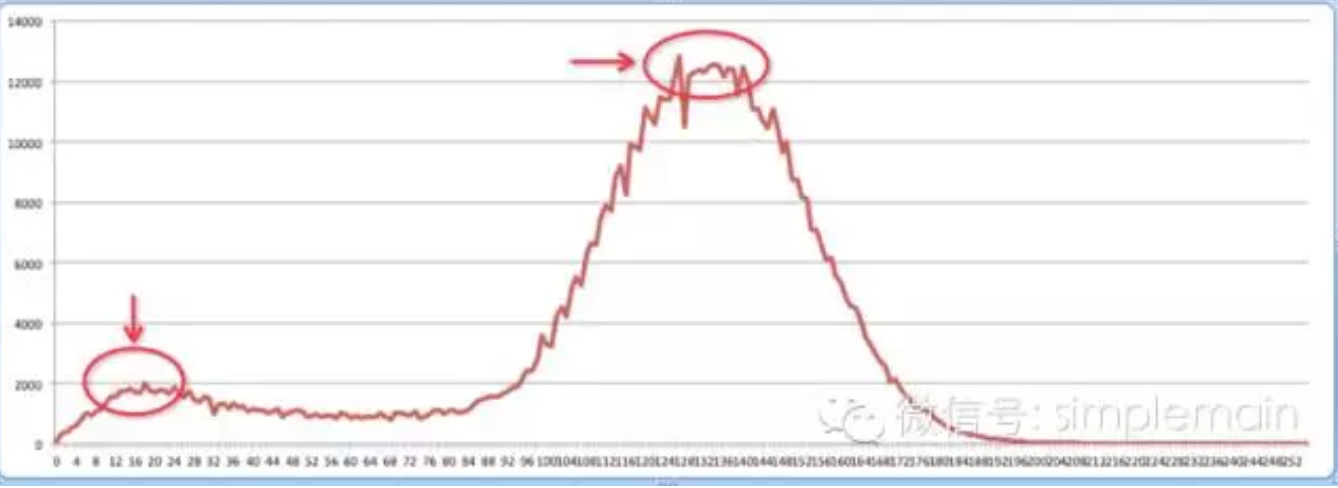
图一
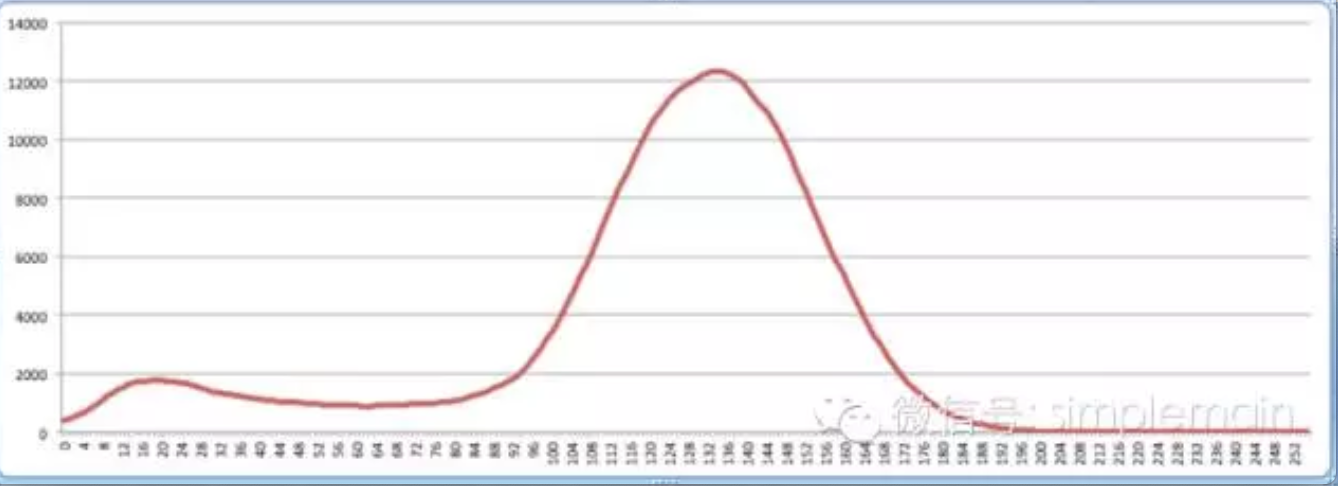
图二
变换后的图更加平滑。
计算方法:
对图中的每个点a[i] = (a[i-1] + a[i] + a[i+1]) / 3(首尾两个点单独处理)。
反复执行,直到剩下N个点比其他点大(N根据你的需要来定)或者连续执行N次(根据性能需要来定)
倾斜校正
根据图像特征不同,通常有两种倾斜校正算法。
一种是图片有明显轮廓的适用基于轮廓提取的校正算法,比如身份证等扫描件。
另一种是文字类型的基于直线探测的校正算法。
基于直线探测的校正算法思路:
- 用霍夫变换探测出图像中所有的直线。
- 计算每个直线的倾斜角度,求平均值。
- 根据角度旋转图片。
水平切割
步骤:
将位图投影到y轴,x值为投影次数累加,比如位图二维矩阵值:
1
2
3
4
0 0 0 0 0 0 0 0 0 0
1 0 1 1 1 1 1 0 0 0
1 0 1 1 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
得到曲线图:
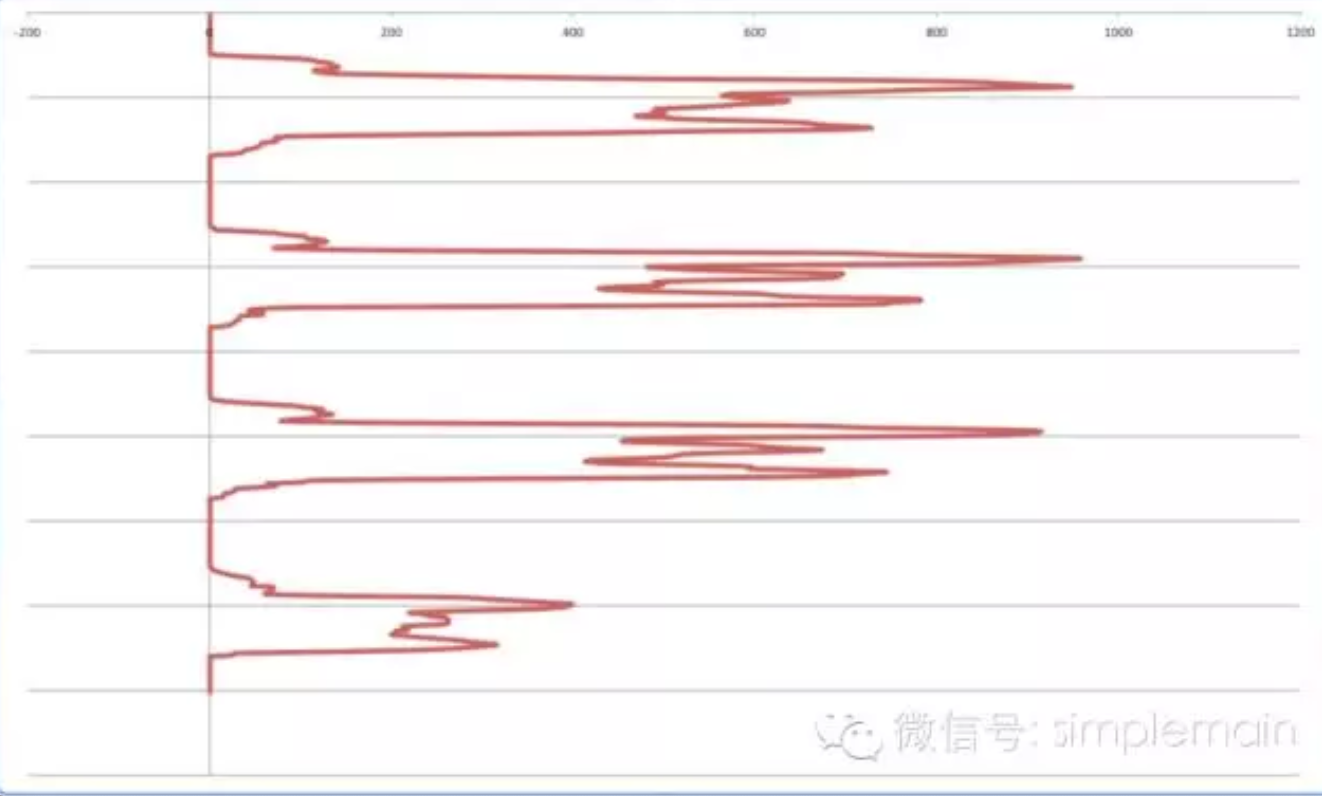
做平滑:
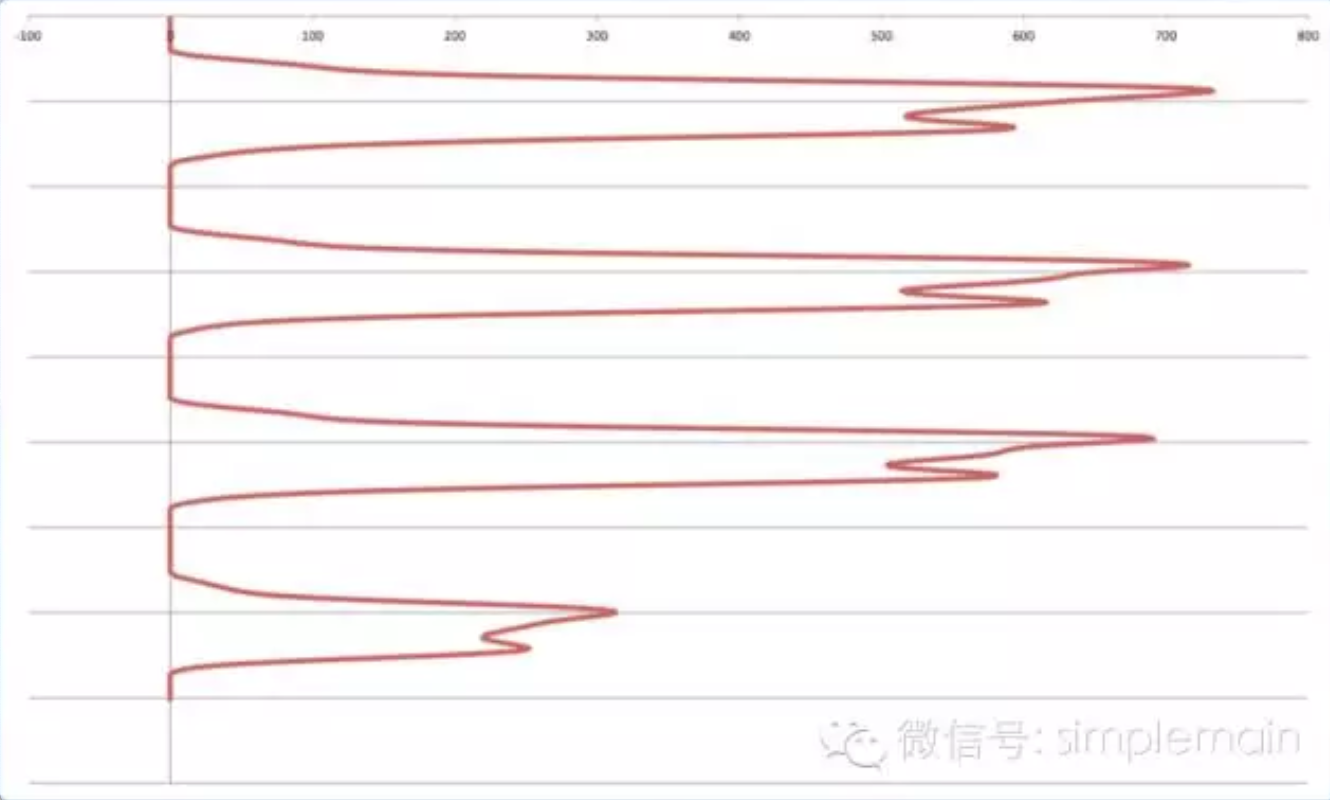
找到波谷,并从波谷切分,就会得到柱状图。
得到的柱状图仍然会有上下留白,需要进一步压缩。压缩方法:计算投影值平均值,将远小于平均值的区域认定为背景。
有些情况是上下结构的字容易被分割成两行,比如:
1
i jump
上面的点可能被分割成单独一行。处理方法是比较相邻两行的高度,如果都比较小,就合并。
垂直切割
垂直切割的方法跟水瓶切割类似。但是可能会出现相邻两个字符在垂直方向上有重叠,比如:
1
Tj
处理方法是计算这行的所有字符的平均宽度,对大于平均宽度的字符,在粘连的薄弱处切割开。
文字识别可选方法
单纯做字符识别,可以有如下解决方案:
- 使用现有第三方产品,如百度OCR。优点是快速开发。缺点:要收费,量大不划算;无法做精度识别优化,只能做些前置后置处理和校正。
- 使用谷歌开源OCR引擎Tesseract。优点:免费;可以自己优化;项目成熟。缺点:汉字支持能力较差,需要花较大经历维持,性价比不高。
- 字符模板匹配法。暴力匹配。优点:简单,做好模板库就行。缺点:只能针对简单场景,字符集多了效率会直线降低,无法用于复杂场景。
- 传统方法,做字符特征提取,输入分类器,得到OCR模型。这是计算机视觉通用方法,在深度学习前,基本都是这个套路。缺点:特征设计需要投入大量人力,成本较高;过度依赖字符切分结果。
- 基于深度学习的CNN字符识别。使用卷积神经网络来做,识别率很高。缺点:需要大量的训练数据;需要一定的计算资源。
- 基于深度学习的端到端OCR技术。识别前不需要进行字符切割。而是对整个图像进行识别。是目前最流行的方法。当前主流的算法有两种:CNN+RNN+CTC;CNN+RNN+Attention。
技术演进路线: 模板匹配法 > 特征工程+分类器 > 深度学习之CNN单字符识别 > 深度学习之端到端OCR
对文档的文字识别已经到达一定水平,如何进一步提高准确率不再成为主题。
业界将目光移向了根据挑战的领域,将场景文本识别(文字检测+文字识别)作为研究课题。

利用深度学习,手写体识别已经有较大进步,但手写文字识别仍然是一个有挑战的课题。
字符模板匹配算法
识别字符前需要做归一化,将字符统一成固定长宽的像素。
归一化会导致某些信息丢失,比如逗号,和引号', 大写ZZ和小写z z,归一化后会很像。因此还需要字符的meta信息作为辅助。
下一步是将归一化字符跟字符集里的标准字符做匹配。
匹配算法:
- 字符像素匹配:逐个像素匹配,匹配度 = 匹配的像素数量 / 总像素数量。缺点不抗干扰。
- 投影区块匹配:分别向x轴、y轴做投影,像素值累加。缺点是统计结果比较粗,比如
a和o不容易区分。 - 九宫格匹配:将图片分割成
3 * 3的格子。 - 重心匹配:确定字符所在区域的位置。可以用来区分逗号和引号。
- 宽高比匹配:可以区分长宽不一样的字符,比如句号
.和竖线| - 不同的算法侧重点不同。需要结合多个算法结果做决策。
CNN字符识别算法
典型网络结构:
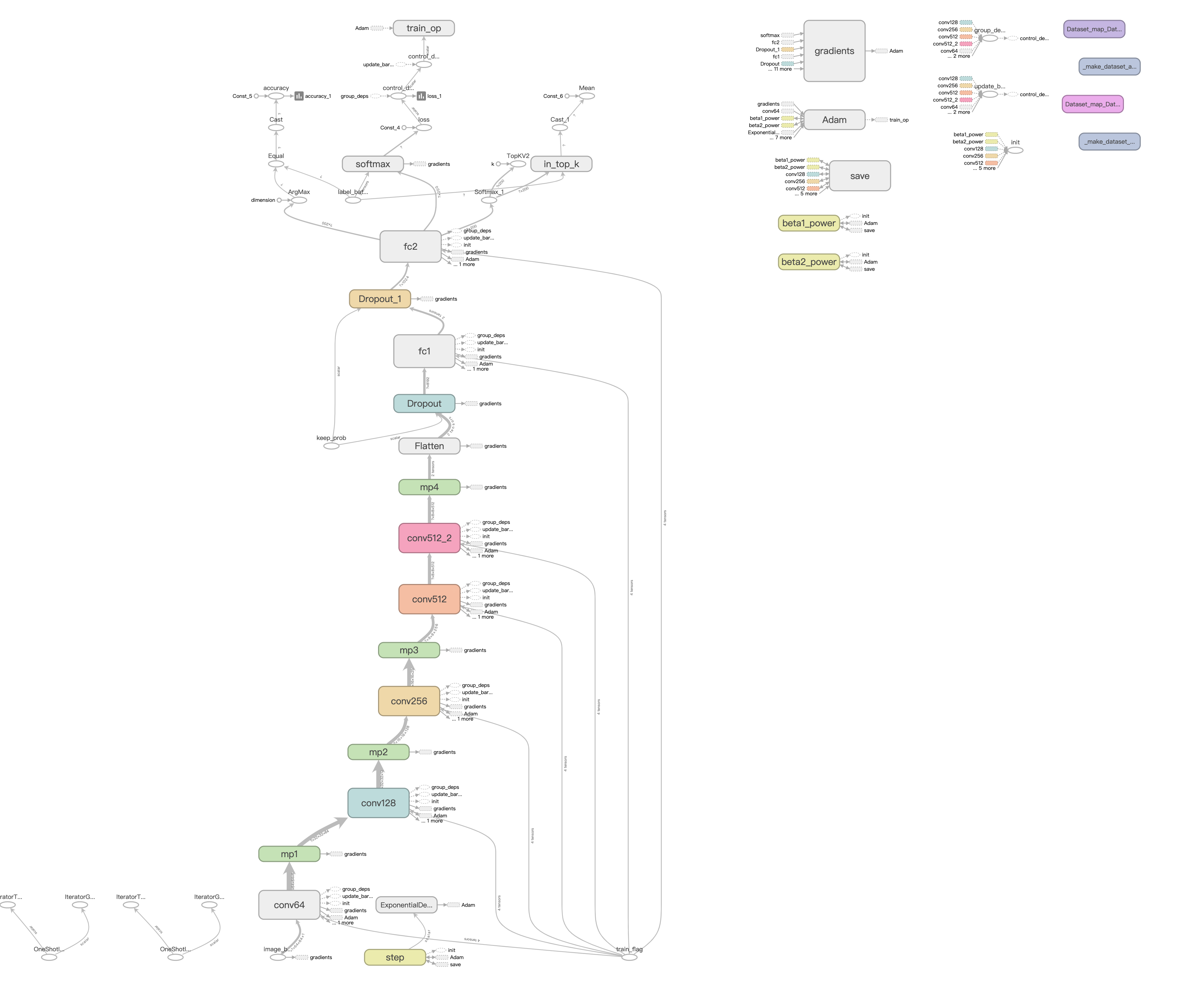
端到端CNN+RNN+CTC算法
TODO
端到端CNN+RNN+Attention算法
TODO
开源项目
[https://github.com/bgshih/crnn] CRNN实现
参考文章
【OCR技术系列之一】字符识别技术总览 https://www.cnblogs.com/skyfsm/p/7923015.html
【OCR技术系列之五】自然场景文本检测技术综述(CTPN, SegLink, EAST) https://www.cnblogs.com/skyfsm/p/9776611.html
【OCR技术系列之七】端到端不定长文字识别CRNN算法详解 https://www.cnblogs.com/skyfsm/p/10335717.html
拍照怎么搜题?(上) https://link.zhihu.com/?target=http%3A//dwz.cn/ocr
拍照怎么搜题?(下) https://link.zhihu.com/?target=http%3A//dwz.cn/ocr2